
热门推荐
 浏览20
浏览20
 浏览18 评论1
浏览18 评论1 浏览17
浏览17
 浏览15
浏览15


在 Deepseek 开源周的第二日,DeepEP 通信库正式发布,成为首个面向混合专家模型(MoE)和专家并行(EP)的开源通信库。DeepEP 通过高效的 GPU 内核优化,为 MoE 模型的训练和推理提供了全栈支持。无论是节点内通信还是节点间通信,DeepEP 都能兼容 NVLink 和 RDMA,同时支持 FP8 调度和 GPU 资源灵活控制。此外,DeepEP 还提供了高吞吐量的训练推理预填充内核和低延迟的推理解码内核,显著提升了模型性能。本文将深入探讨 DeepEP 的核心功能、性能表现以及快速入门指南,帮助开发者更好地理解和应用这一创新工具。

DeepEP 是专为 MoE 模型和专家并行设计的高性能通信库。它通过高吞吐量和低延迟的全到全 GPU 内核,支持混合专家模型的调度与组合。DeepEP 还支持低精度操作,包括 FP8,并通过优化的内核实现了非对称域带宽转发,例如从 NVLink 域到 RDMA 域的数据转发。这些内核不仅适用于训练任务,还能高效完成推理预填充任务。此外,DeepEP 引入了基于钩子的通信-计算重叠方法,无需占用任何 SM 资源,进一步提升了效率。
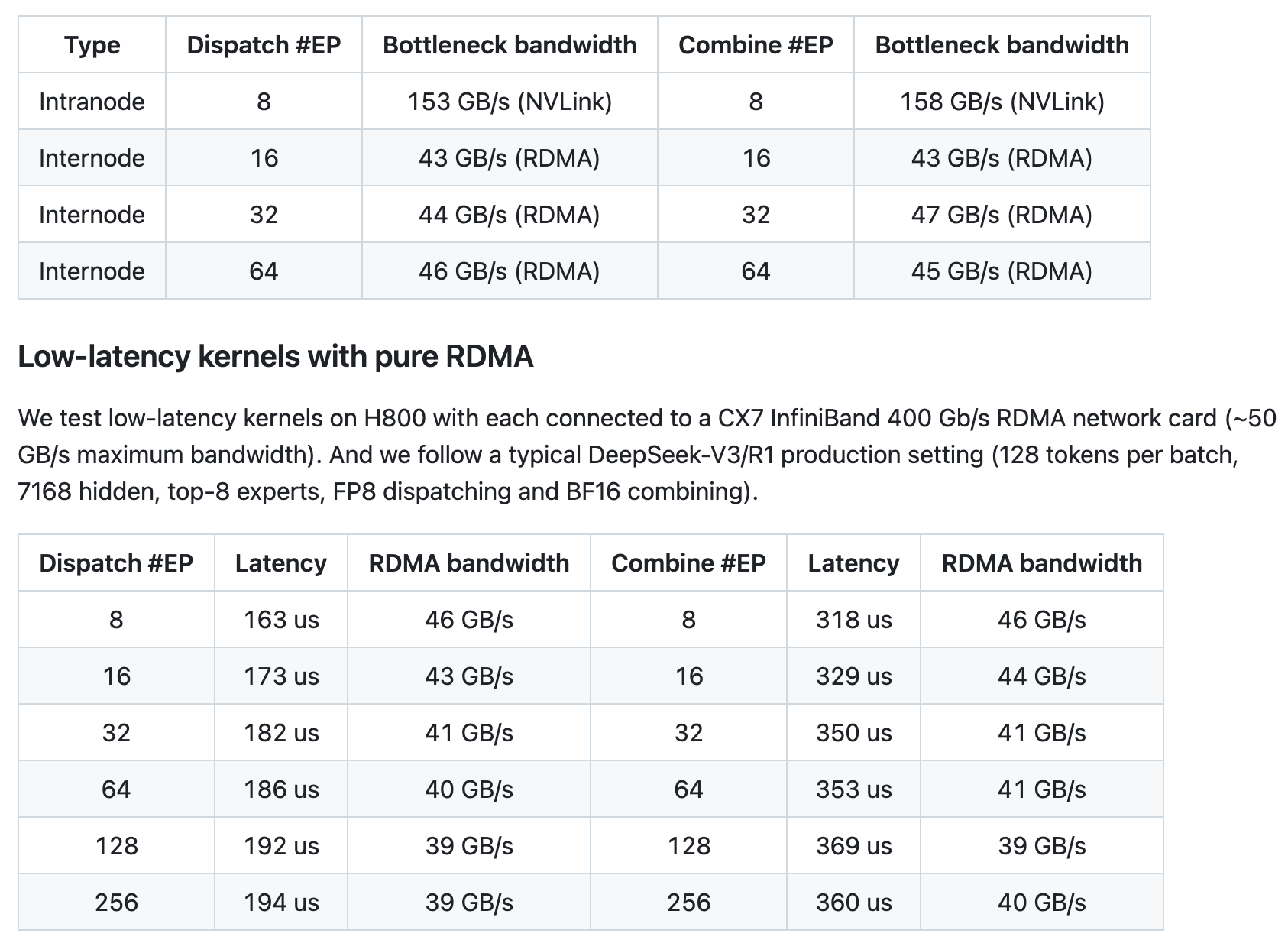
DeepEP 的性能在 H800 GPU 上进行了全面测试。在 NVLink 和 RDMA 转发场景下,DeepEP 展现了卓越的带宽表现。例如,在节点内通信中,NVLink 的最大带宽达到了 153 GB/s,而节点间通信中,RDMA 的最大带宽也稳定在 43 GB/s 以上。对于延迟敏感的推理解码任务,DeepEP 的低延迟内核在纯 RDMA 环境下表现出色,延迟低至 163 微秒,带宽稳定在 46 GB/s 以上。这些数据表明,DeepEP 能够显著提升 MoE 模型的训练和推理效率。
要使用 DeepEP,开发者需要确保系统满足以下要求:Hopper GPU、Python 3.8 及以上版本、CUDA 12.3 及以上版本、PyTorch 2.1 及以上版本。此外,节点内通信需要 NVLink,节点间通信则需要 RDMA 网络。开发者可以通过 DeepEP GitHub 仓库 获取更多详细信息和安装指南。
本站内容依据 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 授权发布。
▎资源使用免责声明:
▎侵权处理:如发现本站存在侵权内容,请在下方留言反馈,我们会尽快处理。
版权信息:本站内容未经书面许可,禁止一切形式的转载。Copyright © 实得惠省钱网. All Rights Reserved.
![]()
本站提供的网盘资源版权均归原作者所有,仅供学习、研究和参考之用,请勿用于商业用途。任何商业使用引发的版权纠纷,责任由使用者自行承担。
本网站由  提供CDN加速/云存储服务
提供CDN加速/云存储服务